Qu’on le souhaite ou non, l’intelligence artificielle est de plus en plus utilisée en médecine, que ce soit par les professionnels de santé ou les patients. Quiconque a une question sur sa santé la pose de plus en plus fréquemment à son chatbot IA préféré. Des médecins commencent même à recevoir des patients avec un rapport de santé établi par un tel outil pour que le médecin « valide » le bilan effectué par la machine. La transition vers une médecine assistée par IA va être aussi rapide que brutale et probablement même irréversible.
Si c’est le cas, il est intéressant de savoir d’où viennent les connaissances médicales des IA ?
De manière très simplifiée, pour obtenir un « docteur IA », il faut entraîner un algorithme avec un volume considérable de données, de préférence d’excellente qualité médicale. Mais est-ce le cas aujourd’hui ?
L’entraînement, c’est à dire la construction de l’expertise médicale d’une IA comme ChatGPT (OpenAI), GEMINI (Google) ou encore MISTRAL (Mistral AI) repose sur 2 étapes :
- Une préparation des données en réalisant les tâches typiques suivantes : normalisation, nettoyage (duplication, non pertinence, données sensibles, biais, etc.) et, pour finir, transformation des données restantes en unités de travail appelées « tokens ».
- Un entraînement, c’est à dire le choix d’un d’algorithme adapté à la tâche à réaliser (par exemple faire un diagnostic médical) et la fourniture de l’ensemble des données préparées pour « apprendre» à réaliser cette tâche de manière automatique, même si l’algorithme n’est pas codé spécifiquement pour réaliser la ou les tâche(s) souhaitée(s).
La précision du résultat repose sur la qualité avec laquelle ces 2 étapes sont réalisées, en particulier la première. C’est celle-ci qui va nous occuper dans cet article.
D’où viennent les données d’entraînement ?
La première réponse est quantitative. D’une manière générale, l’ensemble des données publiquement accessibles sur Internet et quelques données sous licence sont utilisées pour entraîner les grands modèles de langage (LLM). Le graphique suivant[1] présente une idée de l’évolution du volume des données utilisées.
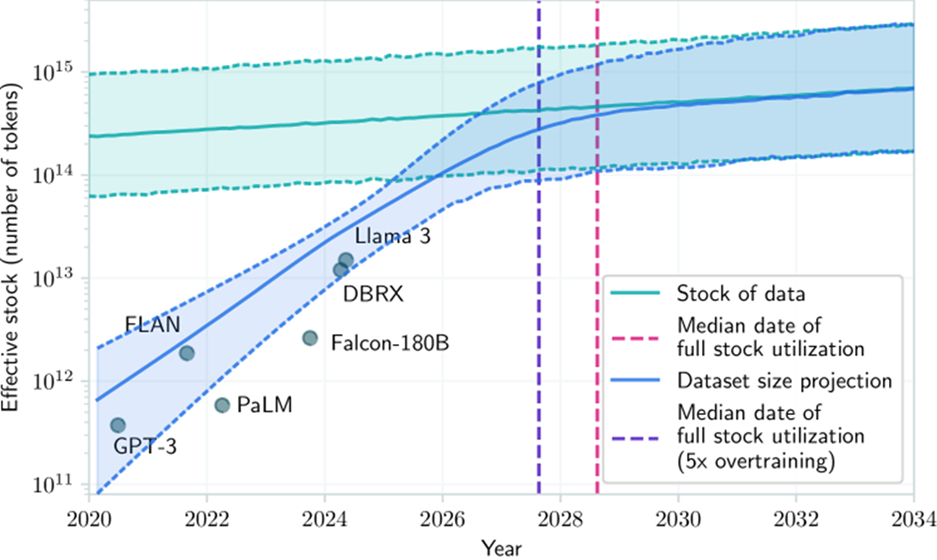
Evolution du stock de données utilisables pour l’entraînement des LLM
Il prévoit qu’à partir de 2030, l’ensemble des données disponibles sur Internet aura été utilisé pour l’entraînement des IA LLM, ce qui va poser la question des données que l’on pourra utiliser par la suite. Pour le moment, cette question n’a pas de réponse robuste.
En outre, même si le chiffre est difficile à vérifier, les données disponibles sont déjà redondantes (Google estime ce chiffre à 60%[2]), du fait des « copier/coller » de données sur tous les supports possibles et imaginables.
En réalité, seule une fraction est utilisable aujourd’hui et la qualité de ce qui est utilisable est hétérogène. De nombreuses techniques sont utilisées pour mesurer la qualité et la diversité des données, comme l’autorité de la source, bien sûr (mais les sources de qualité représentent moins de 10% des données disponibles), le calcul de score (Ex, la qualité de l’orthographe), ou encore l’annotation de données par des humains, même si cette dernière tendance diminue.
Quelle est la transparence des constructeurs d’IA sur leurs données ?
Pour cette question la réponse est loin d’être simple. Par exemple, OpenAI précise dans ses conditions générales[3] que « pour le contenu Internet accessible au public, nous utilisons uniquement des informations librement et ouvertement accessibles sur Internet ». Autre exemple, Google a partagé un aperçu de l’origine des données utilisées pour entraîner Bard (devenu Gemini)[4] : « 12 % de données basées sur C4[5], 12 % de Wikipédia en anglais, 6 % de documents Web en anglais, 6 % de documents Web non anglais, 50 % de forums publics, etc. » On est loin de pouvoir satisfaire notre curiosité avec ces informations.
Pour tenter de répondre à cette question, l’université de Stanford a même créé un index de transparence[6] des modèles d’IA, mis à jour régulièrement. Avec des scores de 40% pour Llama 2 (Meta), 20% pour GPT 4 (OpenAI) ou Mistral, 10% pour Claude (Anthropic) et même 0% pour Gemini 1 (Google). On reste définitivement sur notre faim.
Mais pourquoi un tel manque de transparence ?
Cette pudeur à fournir l’origine des données s’explique avant tout par un enjeu majeur de compétition entre sociétés. Pour simplifier, en termes de valeur ajoutée, une IA repose sur 2 composantes : un algorithme et des données.
Les algorithmes utilisés sont majoritairement basés sur des recherches universitaires accessibles librement. La différenciation algorithmique est très faible entre les sociétés. Ce sont les données accessibles qui font vraiment la différence : leur quantité, qualité et diversité. Divulguer précisément les données utilisées pour l’entraînement revient à fournir son savoir-faire, ses secrets de fabrication. Cela permet de savoir exactement les questions auxquelles saura répondre une IA par rapport à une autre, et donc connaitre sa valeur. À ce titre et sans obligation légale, les sociétés fourniront de moins en moins d’informations dans ce sens.
Les données communément utilisées
À défaut d’avoir la liste exacte, la littérature nous fournit quand même les informations essentielles. Pour l’ensemble des grands modèles de langage, la base de travail est constituée de données provenant de sources quasiment identiques, transformées selon des critères de qualité propres à chaque société. La sophistication croissante de ces transformations est l’un des savoir-faire majeurs de ces entreprises. Les sources les plus connues aujourd’hui sont les suivantes.
Les archives du web. La part majoritaire des données utilisées provient de sources comme Common Crawl[7], une association à but non lucratif qui explore et archive le web depuis 2008. Cette source contient plus de 250 milliards de pages web sauvegardées, représentant l’histoire brute d’Internet. Toutes les publications libres d’accès entrent également dans cette catégorie. Même si les chiffres sont difficiles à vérifier, ce contenu compte probablement pour environ la moitié des données utilisées[8].
Les articles de presse. Ces sources posent de nombreux problèmes juridiques d’utilisation. Initialement récupérées depuis les archives d’internet, les constructeurs concluent de plus en plus d’accords avec les médias pour accéder à ce type de données sans risque juridique, comme les accords signés entre OpenAI et l’Associated Press en 2023[9] ou avec le Monde en France en 2024[10].
Les conversations humaines sur Internet. Les forums publics comme Reddit[11] par exemple, commencent à mettre à disposition leurs données aux géants de l’intelligence artificielle, malgré le désaccord des utilisateurs. Certains articles émettent l’hypothèse que les données de Twitter ou Youtube[12] sont également utilisées. De son côté, le groupe Meta (Facebook, Instagram, WhatsApp) vient juste d’annoncer son intention[13] d’utiliser les données des utilisateurs européens pour entraîner ses modèles, les données des utilisateurs américains étant déjà utilisées[14]. Bref, toutes vos conversations finissent par être écoutées par la machine, même si elles ne sont pas nécessairement identifiantes.
Les sources de savoirs accessibles sont également utilisées : corpus de livres, comme le projet Annas Archive (51 millions de livres[15], soit un tiers des livres existants[16]), l’encyclopédie Wikipédia ou encore des documents de recherche comme arXIV avec plus de 2 millions[17] d’articles de recherche ou Pubmed en médecine et biologie, soit 5 millions de publications[18]. Là encore, les chiffres sont difficiles à vérifier, mais il est probable que ces sources de grande qualité comptent pour moins de 10% des données utilisées.
Les sites de questions/réponses. Cette source fournit des ensembles de questions/réponses validés et sourcés et donc d’excellente qualité pour l’IA. Stackexchange[19] est le principal contributeur de ce type de données, notamment dans le domaine médical.
Le code informatique. Des corpus de codes permettent aux IAs de comprendre les langages de programmation et de générer automatiquement des programmes à partir de conversations. Les données proviennent par exemple de GitHub, une plateforme où des millions de projets informatiques sont hébergés publiquement.
Et pour la médecine ?
En médecine et biologie, on distinguera le développement d’IA dédiées au secteur biomédical (BioGPT, ChemBert) – entraînées uniquement avec des données biomédicales – du développement des modèles généralistes (GPT, GEMINI, META, etc..) qui incorporent des « données médicales » comme une partie de leurs sources. Nous traitons ici de ce second cas de figure.
Pour ce cas, le principe est le même que pour toutes les thématiques : collecter et utiliser toutes les données librement accessibles dans un premier temps. Les sources les plus connues aujourd’hui sont les suivantes.
Les publications médicales[20]. Comme cela a été vu plus haut, les données provenant de sources comme Pubmed (36 millions de citations) ou PMC (8 millions d’articles) par exemple, sont utilisées. Elles constituent la base de la connaissance médicale de l’IA.
Les examens de médecine[21]. Pour apprendre à répondre à des questions via un Chatbot, les examens des étudiants en médecine sont très utilisés comme PubMedQA, MEDQA (examen USMLE américain), MEDMCQA (~190 000 questions/réponses pour les étudiants indiens) ou de plus en plus MultiMedQA, un ensemble de données regroupant les précédents.
Les données médicales. Pour obtenir des données comme des images radiologiques annotées, on utilise également des bases en libre accès comme RADIOPAEDIA[22] (plus de 60 000 cas documentés) ou des bases académiques comme celles de l’université de Stanford CheXpert (plus de 200 000 cas) ou du MIT, physionet[23] (plus de 370 000 cas). Cette dernière recense et fournit également des données de nombreuses constantes médicales comme celles de résultats d’examens biologiques (prise de sang, analyses urinaires, etc…). Plus de 350 bases de données sont disponibles sur physionet.
Les dossiers patients. Pour des questions de législation contraignante, les sociétés ne peuvent pas accéder directement à des données de patients dans les systèmes informatiques des hôpitaux. Pour obtenir des dossiers patients, on utilise également des bases préparées par des structures académiques et de soins. Par exemple, le département de soins intensifs de l’hôpital universitaire de Bern met à disposition la base HiRId contenant les dossiers patients anonymisés de plus de 30 000 admissions.
Ces données sont en constante augmentation pour améliorer la précision des réponses apportées par l’IA en médecine.
Trop peu de données, facile à polluer ?
Une étude intéressante de la revue Nature[24] a été publiée cette année pour savoir dans quelle mesure le fait de polluer les données d’entraînement avec « quelques » fausses informations perturbait les réponses médicales de l’IA. Le résultat est assez perturbant.
D’une part, il est très facile d’ajouter de fausses données, compte tenu du fait que beaucoup de sources de données sont publiques et que leur qualité n’est pas contrôlée. Si l’on n’y prend pas garde, un acteur mal intentionné peut injecter n’importe quelle fausse information dans une source utilisée pour l’entraînement d’une IA.
Mais plus étonnant encore, la quantité de fausses informations n’a pas besoin d’être importante pour corrompre significativement les résultats. Les chercheurs ont montré qu’un volume de 0,01% de données corrompues générait 10% de réponses avec une fausse information. Même un simple volume de 0,001% générait encore 7% de réponses fausses.
Il est évident que des mécanismes de contrôle robustes devront être mise en œuvre.
Un usage qui va se développer avec ou sans transparence
À l’heure où l’IA se développe peu à peu en santé en France, comprendre d’où elle tire ses connaissances paraît être le minimum requis pour une utilisation fiable. Même si la majorité des données utilisées est publique et donc auditable, elles sont souvent redondantes et leur qualité varie fortement. En outre, le manque de transparence des entreprises qui produisent les modèles rend impossible de savoir dans quels domaines de la médecine l’IA possède ou non des compétences.
De son côté, la France avance trop lentement dans la mise à disposition de données de santé permettant d’entraîner la compétence médicale des IA. Les discussions traînent, les lourdeurs administratives freinent tout progrès, et ce ne sont pas les avances timides du Health Data Hub avec le projet PARTAGES[25] en partenariat avec un acteur comme MISTRAL qui vont fondamentalement changer la donne. Les données de santé françaises, qui pourraient jouer un rôle très intéressant dans le développement de l’IA en santé, restent largement inexploitées dans les serveurs hospitaliers ou ceux de prestataires comme Microsoft[26] pour le moment. Même si la sécurité et la confidentialité sont fondamentales pour des données de santé, les techniques d’anonymisation fiables sont très largement disponibles et il est dommage de ne pas les utiliser.
Pour des raisons évidentes d’intérêt médical pour le médecin et le patient, l’utilisation d’un CHATBOT IA pour des questions de santé sera d’un usage courant dans moins de deux ans, si ce n’est pas déjà le cas aujourd’hui. 20%[27] des professionnels de santé en utilisent déjà un dans leur pratique régulière, selon une enquête réalisée par ATAWAO auprès de plusieurs centaines de médecins.
La question pour nous, européens, ne doit pas être de savoir si les réponses de l’IA en santé sont fiables ou non, mais plutôt de comment contribuer à renforcer cette fiabilité en fournissant les données de santé à notre disposition aux acteurs comme MISTRAL (avec un cadre légal clair), qui développent des solutions utilisées par tous dans l’avenir.
Antoine DUBOIS, ATAWAO
Liste des sources utilisées.
[1] ‘Will we run out of data? Limits of LLM scaling based on human-generated data‘, arXiv
[2] www.seroundtable.com/google-60-percent-of-the-internet-is-duplicate-34469.html
[3] help.openai.com/en/articles/7842364-how-chatgpt-and-our-foundation-models-are-developed
[4] www.searchenginejournal.com/google-bard-training-data/478941/
[5] paperswithcode.com/dataset/c4
[6] crfm.stanford.edu/fmti/May-2024/index.html
[7] commoncrawl.org
[8] medium.com/@jelkhoury880/how-have-pre-training-datasets-for-large-language-models-evolved
[9] www.ap.org/media-center/press-releases/2023/ap-open-ai-agree-to-share-select-news-content-and-technology-in-new-collaboration/
[10]www.lemonde.fr/le-monde-et-vous/article/2024/03/13/intelligence-artificielle-un-accord-de-partenariat-entre-le-monde-et-openai_6221836_6065879.html
[11] mashable.com/article/reddit-openai-deal-what-it-means
[12] www.theverge.com/2024/4/6/24122915/openai-youtube-transcripts-gpt-4-training-data-google
[13] about.fb.com/news/2025/04/making-ai-work-harder-for-europeans/
[14] www.businessinsider.com/meta-instagram-facebook-photos-used-in-ai-models-training-2024-5
[15] annas-archive.org/
[16] isbndb.com/blog/how-many-books-are-in-the-world/
[17] en.wikipedia.org/wiki/ArXiv
[18] arxiv.org/pdf/2402.18041
[19] stackexchange.com/sites
[20] A survey of datasets in medicine for large language models, 2024, intelligence & robotics
[21] huggingface.co/blog/leaderboard-medicalllm
[22] radiopaedia.org/
[23] physionet.org/about/database/
[24] www.nature.com/articles/s41591-024-03445-1
[25] curie.fr/actualite/democratiser-lia-generative-en-sante-bpifrance-selectionne-le-projet-partages
[26] www.usine-digitale.fr/article/donnees-de-sante-le-health-data-hub-prepare-une-solution-intercalaire-pour-sortir-d-azure.N2228966
[27] Enquête sur l’usage de l’intelligence artificielle en santé, ATAWAO, 2025, 700 répondants


